
A tokiói székhelyű Sakana AI startup kutatói egy olyan új technikát fejlesztettek ki, amely lehetővé teszi e nyelvi modellek hatekonyabb memóriahasználatát, így segítve a vállalkozásokat e nagy nyelvi modellek (LLM) é mais O modelo do transformador épülő alkalmazások fejlesztési koltségeinek csökkentésében. Az „univerzális transzformátor memória”Elnevezésű technika speciális neurális hálózatok segítségével optimizálja az LLM-eket, közben megtartja e fonts informació bitjeit, é eldobja a felesleges részleteket a contextusukból.
A Transformer-memória optimizálása
O LLM-ek gerincét alkotó Transformer-modellek válaszai e „contextusablakuk” tartalmától függnek – vagyis attól, hogy mit kapnak bemenetként a felhasználóktól.
Um contexto usablak um modelo munkamemoriájának tekinthető. Um contexto usablak tartalmának finomhangolása óriási hatással lehet um modelo teljesítményére, e uma “engenharia imediata” egész területét hívta életre.
Um modelo jelenlegi nagyon hosszú contextousablakokat támogatnak, amelyek több százezer vagy akár milliónyi tokent tartalmaznak (a felhasználók által a súgókba beírt szavak, szórészletek, kifejezések, fogalmak és számok számszerű ábrázolása az LLM-ben).
Ez lehetővé teszi a felhasználók számára, hogy több informaciót zsúfoljanak bele a promptokba. Um hosszabb bejegyzések azonban magasabb számítási koltségeket é lassabb teljesítményt eredményezhetnek. Um prompt optimizálása a felesleges tokenek eltávolítása érdekében e fontes informativas megtartása mellett csökkentheti e költségeket és növelheti a sebességet. A jelenlegi prompt-optimalizálási technikák erőforrás-igényesek, vagy a felhasználóknak kézzel kell tesztelniük e különböző konfigurációkat e promptok méretének csökkentése érdekében.
Neurális figyelmi módulo de memória
A memória universal do transformador e o modelo neurális figyelemmemória (NAMM-ek) são otimizados segítségével. Ezt olyan egyszerű neurális hálózatokkal végzi el, amelyek eldöntik, hogy az LLM memóriájában tárolt minden egyes adott tokent „megjegyezzenek” vagy „elfelejtsenek”.
„Ez az új képesség lehetővé teszi a transzformátorok számára, hogy a nem hasznos vagy felesleges részleteket elvessék. Egyúttal e legkritikusabb informaciókra összpontosítanak, ami szerintünk kulcsfontosságú e hosszú kontextusú gondolkodást igénylő feladatokhoz.”- írják um kutatók.
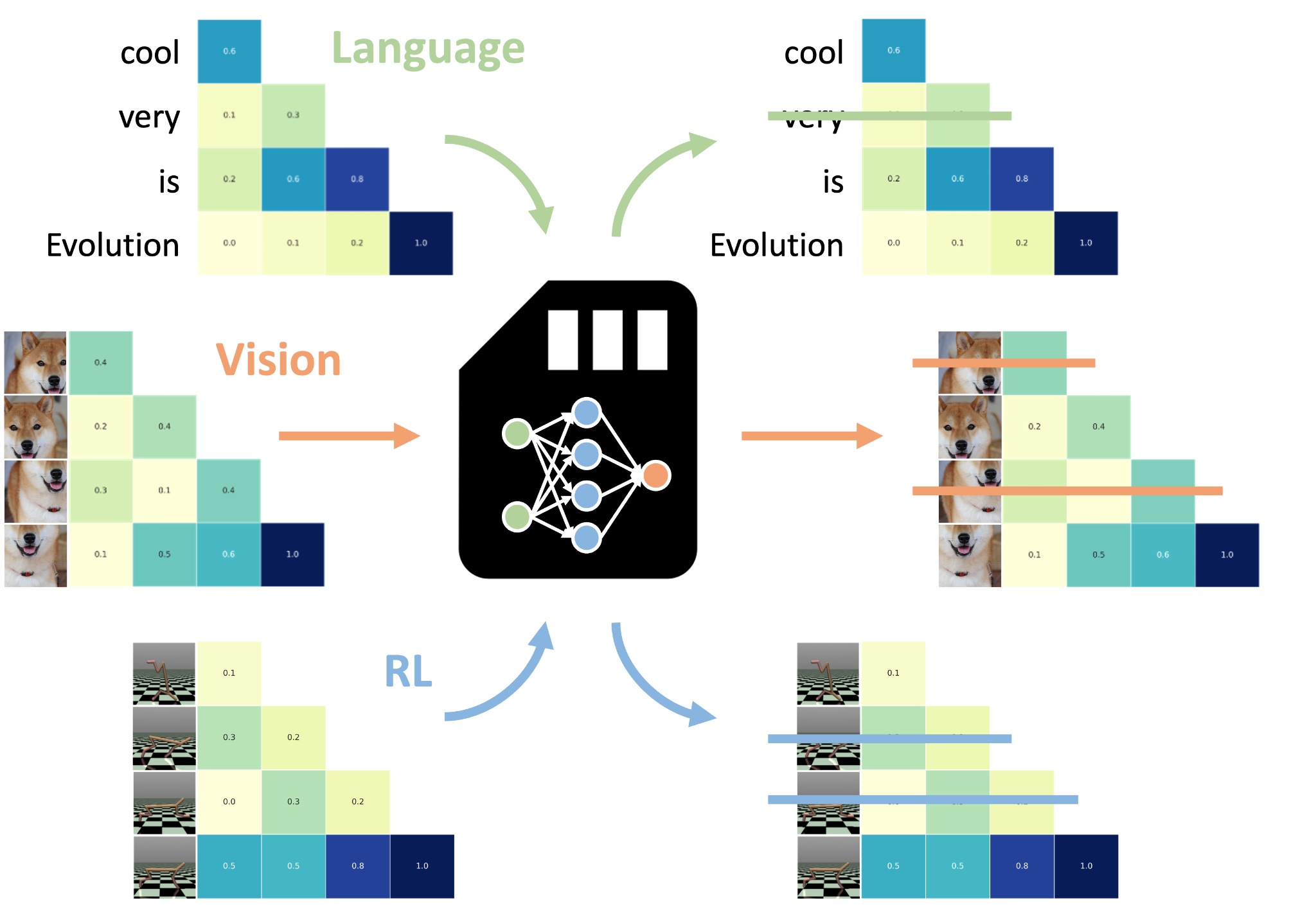
Um NAMM-eket az LLM-től elkülönítve képzik ki, és kovetkeztetéskor kombinálják az előre betanított modellel, ami rugalmassá é könnyen alkalmazhatóvá teszi őket. Ugyanakkor hozzáférésre van szükségük e modell belső activacióihoz. Ez azt jelenti, hogy csak nyílt forráskódú modellekhez alkalmazhatók.
Um Sakana AI által kifejlesztett mais técnico hasonlóan um NAMM-eket é um algoritmo desenvolvido segítségével képzik ki a gradiens alapú optimizálási módszerek helyett. A evolução do algoritmo e do modelo de telefone móvel iteratív mutaciójával é próbálgatással történő kiválasztásával optimizálják a NAMM-okat a hatékonyság é um teljesítmény szempontjából. Ez különösen fontos, mivel a NAMM-ek egy nem diferenciálható célt próbálnak elérni: a tokenek megtartását vagy eldobását.
Um NAMM-ek az LLM-ek figyelmi rétegein működnek, um Transformer architektúra egyik kulcsfontosságú komponensén, amely meghatározza az egyes tokenek kapcsolatait é fontosságát a modell kontextusablakában. Um figyelem értékei alapján a NAMM-ek meghatározzák, hogy mely tokeneket kell megtartani, é melyeket lehet eldobni az LLM contextusablakából. Ez a figyelemalapú mechanizmus lehetővé teszi, hogy egy betanított NAMM-et különböző modelleken további módosítás nélkül használjunk. Például egy csak szöveges adatokon képzett NAMM további képzés nélkül alkalmazható látás vagy multimodális modellekre.
Memória universal működés közben
A memória universal de transformação de memória é um conceito de memória que pode ser testado e cortado, egy NAMM-ot képeztek ki egy nyílt forráskódú Meta Llama 3-8B modellre. Kísérleteik azt mutatják, hogy a NAMM-ekkel a Transformer-alapu modellek jobban teljesítenek a természetes nyelvi és kodolási problémákon, nagyon hosszú szekvenciákon. Eközben a felesleges tokenek elvetésével a NAMM lehetővé tette az LLM modell számára, hogy a feladatok végrehajtása során a gyorsítótár memóriájának akár 75%-át is megtakarítsa.
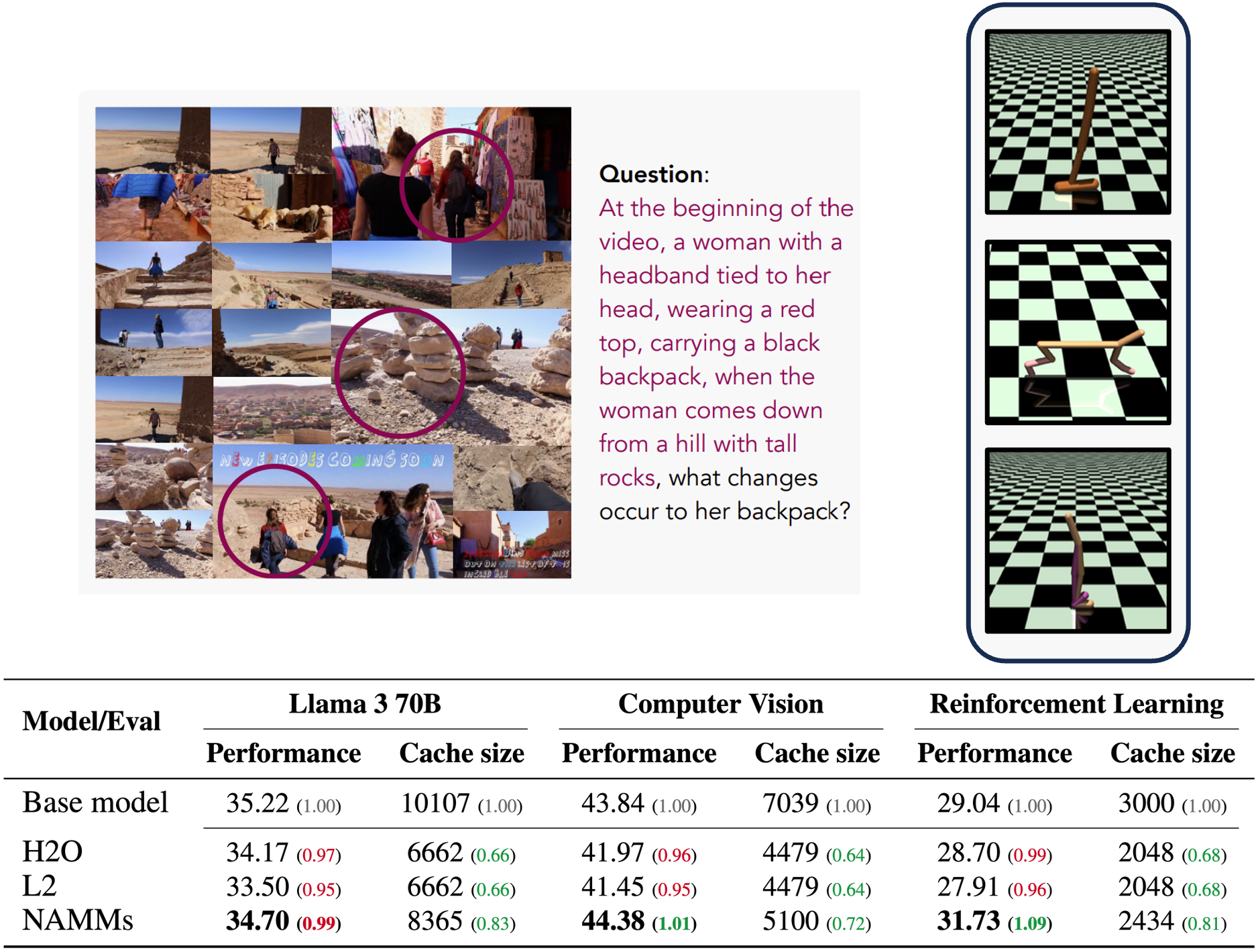
Um modelo de Llama 70B változatán, valamint mais modalitásokhoz és feladatokhoz tervezett Transformer-modelleken is tesztelték, mint például a Llava (számítógépes látás) é um Transformador de Decisão (megerősítéses tanulás).
„A NAMM-ek még ezekben a nem elosztott beállításokban é megőrzik előnyeiket azáltal, hogy olyan tokeneket dobnak ki, mint a felesleges videoképek é um szuboptimális cselekvések. Ezzel lehetővé válik, hogy az új alapmodellek e teljesítmény javítása érdekében e legrelevánsabb informaciókra összpontosítsanak.”- írják a kutatók.
Feladatfüggő viselkedés
Egy maisik érdekes eredmény, hogy a NAMM-ok automatikusan a feladat függvényében alakítják viselkedésüket.
Például a kódolási feladatok esetében a modell elveti a tokenek egybefüggő darabjait, amelyek megfelelnek e megjegyzéseknek é um código végrehajtását nem befolyásoló szóközöknek.
Másrészt a természetes nyelvi feladatoknál a modell elveti azokat a tokeneket, amelyek nyelvtani redundanciát jelentenek, é nem befolyásolják a szekvencia jelentését.
A kutatók közzétették e saját NAMM-ok létrehozásához szükséges kódot. Com a tecnologia olyan, a memória transzformációs da hortelã para o universo, nagyon hasznosak lehetnek e dois milhões de tokens feldolgozását végző vállalati alkalmazások számára. Ezáltal a sebességnövekedés é um költségcsökkentés előnyeit élvezhetik. Um képzett NAMM újrafelhasználhatósága emellett sokoldalúan használható eszközzé teszi azt a vállalat különböző alkalmazásaiban.
Um jövőre nézve um kutatók fejlettebb technikákat javasolnak, például um NAMM-ek használatát az LLM-ek képzése során, hogy tovább bővítsék memóriaképességeiket.
„Ez a munka még csak a memóriamodellek új osztályában rejlő lehetőségek kiaknázásának kezdetét jelenti. Ezek várhatóan számos új lehetőséget kínálhatnak e transzformátorok jövőbeli gerációinak fejlesztéséhez.”- írják a kutatók.
https://www.youtube.com/watch?v=videoseries
