Relé de bloco compacto, BIP152é um método para reduzir a quantidade de largura de banda usada para propagar novos blocos para nós completos.
Resumo
Usando técnicas simples é possível reduzir a quantidade de largura de banda necessária para propagar novos blocos para nós completos quando eles já compartilham grande parte do mesmo conteúdo do mempool. Os peers enviam “esboços” de blocos compactos aos peers receptores. Esses esboços incluem as seguintes informações:
- O cabeçalho de 80 bytes do novo bloco
- Identificadores de transação abreviados (txids), projetados para evitar ataques de negação de serviço (DoS).
- Algumas transações completas que o peer remetente prevê que o peer destinatário ainda não possui
O peer receptor então tenta reconstruir todo o bloco usando as informações recebidas e as transações já em seu pool de memória. Se ainda estiver faltando alguma transação, ele irá solicitá-la ao peer transmissor.
A vantagem desta abordagem é que as transações só precisam ser enviadas uma vez, na melhor das hipóteses – quando são originalmente transmitidas – proporcionando uma grande redução na largura de banda geral.
Além disso, a proposta do relé de bloco compacto também oferece um segundo modo de operação (chamado modo de alta largura de banda), onde o nó receptor solicita a alguns de seus pares que enviem novos blocos diretamente, sem pedir permissão primeiro, o que pode aumentar a largura de banda (porque dois pares podem tentar enviar o mesmo bloco ao mesmo tempo), mas reduz ainda mais a quantidade de tempo necessária. leva blocos para chegar (latência) em conexões de alta largura de banda.
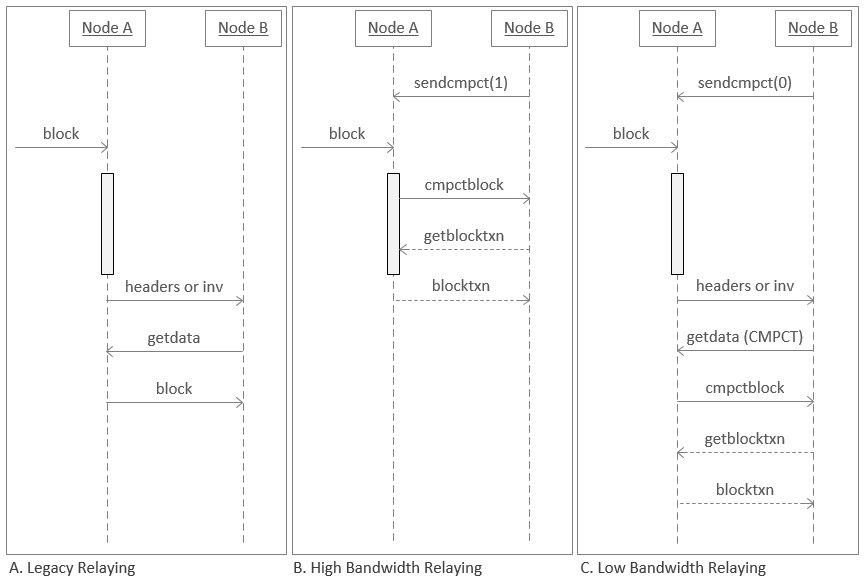
O diagrama abaixo mostra a maneira como os nós enviam blocos atualmente em comparação com os dois modos de operação do relé de bloco compacto. A caixa cinza na linha do tempo do nó A representa o período em que ele está realizando a validação.
-
Em Retransmissão Legada, um bloco é validado (a barra cinza) pelo Nó A, que então envia um
invmensagem para o Nó B solicitando permissão para enviar o bloco. O nó B responde com uma solicitação (getdata) para o bloco e o Nó A o envia. -
Em Retransmissão de alta largura de banda, O nó B usa
sendcmpt(1)(enviar compacto) para informar ao Nó A que deseja receber blocos o mais rápido possível. Quando um novo bloco chega, o Nó A realiza alguma validação básica (como validar o cabeçalho do bloco) e então automaticamente começa a enviar o cabeçalho, os txids abreviados e a transação perdida prevista (conforme descrito acima) para o Nó B. O Nó B tenta reconstruir o bloquear e solicitar quaisquer transações que ainda estejam faltando (getblocktxn), que o Nó A envia (blocktxn). Em segundo plano, ambos os nós completam a validação completa do bloco antes de adicioná-lo às suas cópias locais da blockchain, mantendo a mesma segurança completa do nó de antes. -
Em Retransmissão de baixa largura de banda, O nó B usa
sendcmpt(0)para informar ao Nó A que deseja minimizar o uso de largura de banda tanto quanto possível. Quando um novo bloco chega, o Nó A o valida totalmente (para não retransmitir nenhum bloco inválido). Em seguida, ele pergunta ao Nó B se deseja o bloco (inv) para que se o Nó B já tiver recebido o bloco de outro ponto, ele possa evitar baixá-lo novamente. Se o Nó B quiser o bloco, ele o solicitará em modo compacto (getdata(CMPCT)) e o Nó A envia o cabeçalho, os txids curtos e as transações perdidas previstas. O Nó B tenta reconstruir o bloco, solicita quaisquer transações que ainda estejam faltando e o Nó A envia essas transações. O nó B então valida totalmente o bloco normalmente.
Quais são alguns benchmarks úteis para isso?
Um anúncio de bloco médio completo de 1 MB pode ser reconstruído pelo nó receptor com um esboço de bloco de 9 KB, mais sobrecarga para cada transação no bloco que não está no mempool do nó receptor. Os maiores esboços de bloco vistos atingem alguns bytes ao norte de 20 KB.
Ao executar experimentos ao vivo no modo de ‘alta largura de banda’ e ter nós pré-preenchendo até 6 transações, podemos esperar ver bem mais de 90% dos blocos se propagarem imediatamente, sem a necessidade de solicitar quaisquer transações ausentes. Mesmo sem preencher previamente nenhuma transação, exceto a coinbase, os experimentos mostram que podemos ver bem ao norte de 60% dos blocos se propagando imediatamente, o restante exigindo uma viagem de ida e volta de rede adicional completa.
Como a diferença entre mempools e blocos para nós aquecidos raramente é superior a 6 transações, isso significa que o relé de bloco compacto atinge uma redução drástica na largura de banda de pico necessária.
Para reduzir o número de coisas que precisam ser revisadas na implementação inicial, apenas a transação coinbase será enviada preventivamente.
Porém, nos experimentos descritos, o nó remetente utilizou uma fórmula simples para escolher quais transações enviar: quando o Nó A recebia um bloco, ele verificava quais transações estavam no bloco, mas não em seu mempool; essas foram as transações que ele previu que seu par não tinha. O raciocínio é que (sem informações adicionais) as transações que você não conhecia são provavelmente também as transações que seus pares desconhecem. Com esta heurística básica, observou-se uma grande melhoria, ilustrando que muitas vezes as soluções mais simples são as melhores.
Como a Fast Relay Network influencia isso?
O Rede de retransmissão rápida (FRN) consiste em duas peças:
O conjunto de nós selecionados na FRN foi cuidadosamente escolhido com retransmissão mínima em todo o mundo como prioridade número um. A falha desses nós resultaria em um aumento significativo de desperdício de poder de hash e potencial centralização adicional da mineração. A grande maioria do hashpower de mineração hoje se conecta a esta rede.
O FBRP original é como os nós participantes comunicam informações de bloco entre si. Os nós rastreiam quais transações eles enviam uns aos outros e retransmitem diferenciais de blocos com base nesse conhecimento. Este protocolo é quase ideal para comunicação servidor-cliente um-para-um de novos blocos. Mais recentemente, um protocolo baseado em UDP e Forward Error Correction (FEC), denominado RN-NextGeneration, foi implantado para teste e uso por mineradores. No entanto, esses protocolos exigem uma topologia de retransmissão mal conectada e são mais frágeis do que uma rede p2p mais geral. Melhorias no nível do protocolo usando blocos compactos reduzirão a lacuna de desempenho entre a rede de nós selecionada e a rede p2p em geral. A maior robustez da rede p2p e a velocidade de propagação de blocos em geral desempenharão um papel no desenvolvimento da rede no futuro.
Isso dimensiona o Bitcoin?
Esse recurso tem como objetivo economizar largura de banda de bloco de pico para nós, reduzindo picos de largura de banda que podem degradar a experiência do usuário final na Internet. No entanto, as pressões de centralização da mineração existem em grande parte devido à latência da propagação do bloco, conforme descrito no vídeo a seguir. Os blocos compactos versão 1 não foram projetados principalmente para resolver esse problema.
Espera-se que os mineradores continuem a usar o Rede de retransmissão rápida até que uma solução de menor latência ou mais robusta seja desenvolvida. No entanto, melhorias no protocolo p2p básico aumentarão a robustez no caso de falha do FRN e talvez reduzirão a vantagem das redes de retransmissão privadas, fazendo com que não valha a pena executá-las.
Além disso, os experimentos realizados e os dados coletados utilizando a primeira versão de blocos compactos informarão o projeto das melhorias futuras que esperamos que sejam mais competitivas com o FRN.
Quem se beneficia com os blocos compactos?
-
Usuários de nó completo que desejam retransmitir transações, mas que possuem largura de banda de Internet limitada. Se você simplesmente deseja economizar o máximo de largura de banda possível e ao mesmo tempo retransmitir blocos para pares, existe um
blocksonlymodo já disponível a partir do Bitcoin Core v0.12. O modo somente blocos só recebe transações quando elas são incluídas em um bloco, portanto, não há sobrecarga extra de transação. -
A rede como um todo. Diminuir os tempos de propagação de blocos na rede p2p cria uma rede mais saudável com uma melhor margem de segurança de retransmissão de linha de base.
Qual é o cronograma de codificação, teste, revisão e implantação da propagação de blocos compactos?
A primeira versão de blocos compactos foi atribuída BIP152tem uma implementação funcional e está sendo testado ativamente pela comunidade de desenvolvedores.
Como isso pode ser adaptado para uma retransmissão p2p ainda mais rápida?
Melhorias adicionais no esquema de blocos compactos podem ser feitas. Eles estão relacionados ao RN-NG e são duplos:
-
Primeiro, substitua a transmissão TCP de informações de bloco pela transmissão UDP.
-
Em segundo lugar, lide com pacotes descartados e envie preventivamente dados de transações ausentes usando códigos FEC (Forward Error Correction).
A transmissão UDP permite que os dados sejam enviados pelo servidor e digeridos pelo cliente tão rápido quanto o caminho permitir, sem se preocupar com a queda intermitente de pacotes. Um cliente preferiria receber pacotes fora de ordem para construir o bloco o mais rápido possível, mas o TCP não permite isso.
Para lidar com os pacotes descartados e receber dados de blocos não redundantes de vários servidores, serão empregados códigos FEC. Um código FEC é um método de transformar os dados originais em um código redundante, permitindo a transmissão sem perdas, desde que uma certa porcentagem de pacotes chegue ao seu destino, onde os dados necessários são apenas ligeiramente maiores que o tamanho original dos dados.
Isso permitiria que um nó começasse a enviar um bloco assim que o recebesse e permitiria que os destinatários reconstruíssem os blocos transmitidos de vários pares simultaneamente. Todo esse trabalho continua a se basear no trabalho de blocos compactos já concluído. Esta é uma extensão de médio prazo e o desenvolvimento está em andamento.
Essa ideia é nova?
A ideia de usar filtros bloom (como os usados em BIP37 filteredblocks) para transmitir blocos com mais eficiência foi proposto há alguns anos. Também foi implementado por Pieter Wuille (sipa) em 2013, mas ele descobriu que a sobrecarga tornava a transferência mais lenta.
(#bitcoin-dev, public log (excerpts))
(2013-12-27)
09:12 TD: i'm working on bip37-based block propagation
(...)
10:27 sipa: bip37 doesnt really make sense for block download, no? why do you want the filtered merkle tree instead of just the hash list (since you know you want all txn anyway)
(...)
15:14 BlueMatt: the overhead of bip37 for full match is something like 1 bit per transaction, plus maybe 20 bytes per block or so
15:14 over just sending the txid list
(2013-12-28)
00:11 BlueMatt: i have a ~working bip37 block download branch, but it's buggy and seems to miss blocks and is very slow
00:15 BlueMatt: haven't investigated, but my guess is transactions that a peer assumes we have and doesn't send again
00:15 while they already have expired from our relay pool
(...)
00:17 if we need to ask for missing transactions, there is an extra roundtrip, which makes it likely slower than full block download for many connections
00:18 you also cant request missing txn since they are no longer in mempool (...)
00:21 sounds like we really do need a protocol extension for this.
(...) 00:23 gmaxwell: i don't see how to do it without extra roundtrip
00:23 send a list of txn in your mempool (or bloom filter over them or whatever)!Conforme observado no trecho, a simples extensão do protocolo para suportar o envio de hashes de transações individuais para solicitações de transações, bem como transações individuais em blocos, acabou permitindo que o esquema de blocos compactos fosse muito mais simples, resistente a DoS e mais eficiente.


